MiniGPT-4 AI 可以像 GPT-4 处理复杂的视觉语言任务
MiniGPT-4 是开源模型,由博士的学历团队开发,MiniGPT-4 具有与 GPT-4 所描绘的相似的能力,例如详细的图像描述生成和从手写草稿创建网站
GPT-4 是 OpenAI 最新发布的大型语言模型。 它的多模性质使其有别于所有先前引入的 LLM。 GPT 的 transformer 架构是著名的 ChatGPT 背后的技术,使其能够通过超好的自然语言理解来模仿人类。
GPT-4 在解决生成详细而精确的图像描述、解释不寻常的视觉现象、使用手写文本指令开发网站等任务方面表现出了巨大的性能。 一些用户甚至用它来构建视频游戏和 Chrome 扩展,并解释复杂的推理问题。
GPT-4 卓越性能背后的原因尚不完全清楚。 最近发表的一篇研究论文的作者认为,GPT-4 的高级能力可能是由于使用更高级的大型语言模型。先前的研究表明 LLM 如何具有巨大的潜力,这在较小的模型中大多不存在。
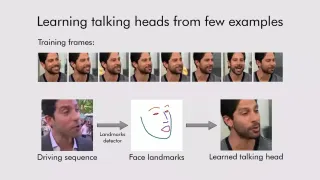
因此,作者提出了一种名为 MiniGPT-4 的新模型来详细探索该假设。MiniGPT-4 是开源模型,能够像 GPT-4 一样执行复杂的视觉语言任务。
由博士的学历团队开发。来自沙特阿拉伯阿卜杜拉国王科技大学的学生发现,MiniGPT-4 具有与 GPT-4 所描绘的相似的能力,例如详细的图像描述生成和从手写草稿创建网站。
MiniGPT-4 使用称为 Vicuna 的高级 LLM 作为语言解码器,它建立在 LLaMA 之上,据报道达到 GPT-4 评估的 ChatGPT 质量的 90%。 MiniGPT-4 使用 BLIP-2(Bootstrapping Language-Image Pre-training)的预训练视觉组件,并添加了一个投影层,通过冻结所有其他视觉和语言组件,将编码的视觉特征与 Vicuna 语言模型对齐。

当被要求从图片输入识别问题时,MiniGPT-4 表现出很好的结果。 它提供了一种解决方案,该解决方案基于用户提供的病害植物图像输入,并提示询问植物出了什么问题。
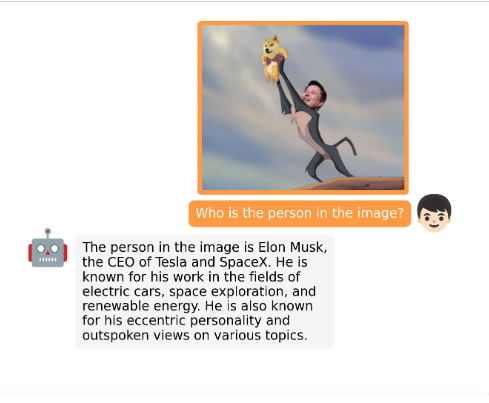
它甚至可以发现图像中不寻常的内容、撰写产品广告、通过观察美味食物照片生成详细食谱、根据图像创作说唱歌曲,以及直接从图像中检索有关人物、电影或艺术的事实。
根据他们的研究,该团队提到训练一个投影层可以有效地将视觉特征与 LLM 对齐。 MiniGPT-4 只需要在 4 个 A100 GPU 训练大约 10 个小时。 此外,团队还分享开发高性能 MiniGPT-4 模型是多么困难。
因为这可能会导致重复的短语或支离破碎的句子,仅使用来自公共数据集的原始图像-文本对将视觉特征与 LLM 对齐。为了克服这一限制,MiniGPT-4 需要使用高质量、对齐良好的数据集进行训练,从而通过生成更自然和连贯的语言输出来增强模型的可用性。
由于其卓越的多模态生成能力,MiniGPT-4 似乎是一个很有前途的发展。最重要的特征之一是它的高计算效率,而且它只需要大约 500 万个对齐的图像-文本对来训练投影层。 代码、预训练模型和收集的数据集可用